Math 143 C/E, Spring 2001
IPS Reading Questions
Chapter 8, Section 2
- The data in the table at the top of p. 603 can be
thought of as having been collected using questionnaires
which asked for two pieces of information (i.e., two
variables) from each respondent: the gender of the
respondent, and the respondent's status as a binge
drinker. A different type of table (than the one on
p. 603), called a two-way table, can be constructed
to summarize the information collected using such a
survey. While you have yet to do any reading regarding
two-way tables (and I am not asking you to do any now
either), try your hand at constructing one following
this brief description:
Along the top, write column headers for each value
of one of the two variables, perhaps “gender”.
Along the rows, write down row “headings” for each
value of the other variable (this would be “drinking
status” if you used “gender” for the columns). You
should now have headings for two columns and two rows.
Add a third column for “Totals” and similarly a third
row for “Totals”. Now fill in the 9 entries of the
table with the appropriate counts.
Compare your result to Table 2.14 on p. 194.
- Why does it make more sense when performing a test
of significance for the difference in two (independent)
proportions to use a pooled estimate (defined at the
bottom of p. 604) in the calculation of the spread
sD than to use one of the proportions
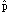 1
or 2
that arise from the samples?
1
or 2
that arise from the samples?
- The authors say in several places that the sample sizes
n1 and n2 should be large. At the top of p. 606,
they remind us why this is necessary: because we are
using the normal approximation to distributions that
truly are binomial (at least, binomial for
the counts X1 and X2). For 1-sample procedures,
what was the criterion that had to be met in order to
use such a binomial approximation? How has this
criterion been modified for 2-sample procedures?
File translated from
TEX
by
TTH,
version 2.87.
On 29 Mar 2001, 10:06.